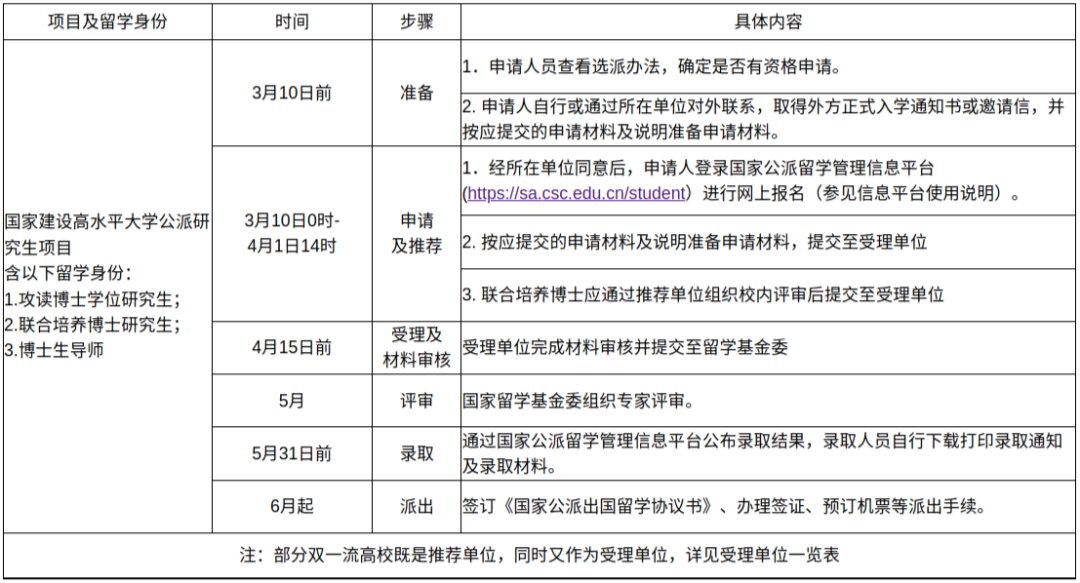
文章目录[隐藏]
ChatGLM-6B介绍
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于General Language Model (GLM)架构,具有 62 亿参数。
https://huggingface.co/THUDM/chatglm-6b
ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
ChatGLM-6B-INT8
https://huggingface.co/THUDM/chatglm-6b-int8
对 ChatGLM-6B 中的 28 个 GLM Block 进行了 INT8 量化,没有对 Embedding 和 LM Head 进行量化。
量化后的模型理论上 8G 显存(使用 CPU 即内存)即可推理,具有在嵌入式设备(如树莓派)上运行的可能。
ChatGLM-6B-INT4
https://huggingface.co/THUDM/chatglm-6b-int4
对 ChatGLM-6B 中的 28 个 GLM Block 进行了 INT4 量化,没有对 Embedding 和 LM Head 进行量化。
量化后的模型理论上 6G 显存(使用 CPU 即内存)即可推理,具有在嵌入式设备(如树莓派)上运行的可能。
ChatGLM-6B基础使用
ChatGLM-6B已经托管在huggingface,可以直接通过hg进行调用:
fromtransformersimportAutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)# 加载模型,可以设置不同的版本model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()# 第一次对话response, history = model.chat(tokenizer,"你好", history=[]) print(response)# 第二次对话response, history = model.chat(tokenizer,"晚上睡不着应该怎么办", history=history) print(response)
在使用的过程中,response为当前对话的返回结果,history为累计对话的历史信息。
ChatGLM-6B 使用示例
自我认知

提纲写作

文案写作

邮件写作助手

信息抽取

角色扮演

评论比较

旅游向导

ChatGLM-6B 局限性
由于 ChatGLM-6B 的小规模,其能力仍然有许多局限性。以下是我们目前发现的一些问题:
模型容量较小:6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;它也不擅长逻辑类问题(如数学、编程)的解答。
产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。(内容可能具有冒犯性,此处不展示)
英文能力不足:ChatGLM-6B 训练时使用的指示/回答大部分都是中文的,仅有极小一部分英文内容。因此,如果输入英文指示,回复的质量远不如中文,甚至与中文指示下的内容矛盾,并且出现中英夹杂的情况。
易被误导,对话能力较弱:ChatGLM-6B 对话能力还比较弱,而且 “自我认知” 存在问题,并很容易被误导并产生错误的言论。例如当前版本的模型在被误导的情况下,会在自我认知上发生问题。
【竞赛报名/项目咨询+微信:mollywei007】
帮筛选 帮规划 帮协调 一站式服务