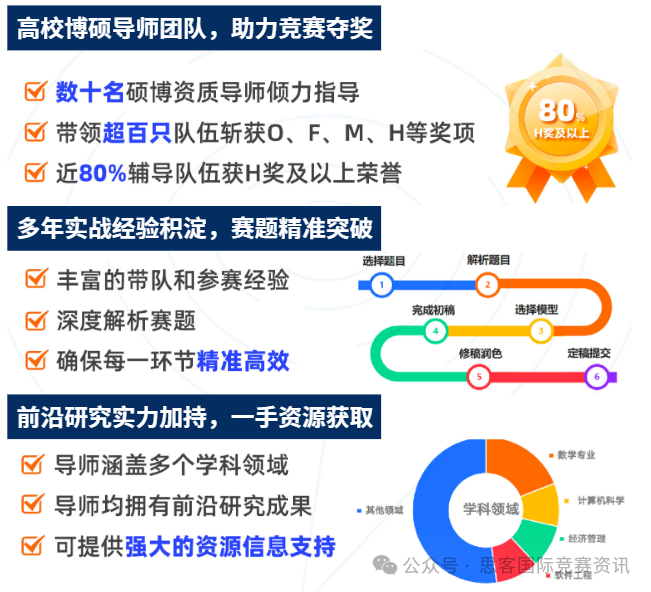
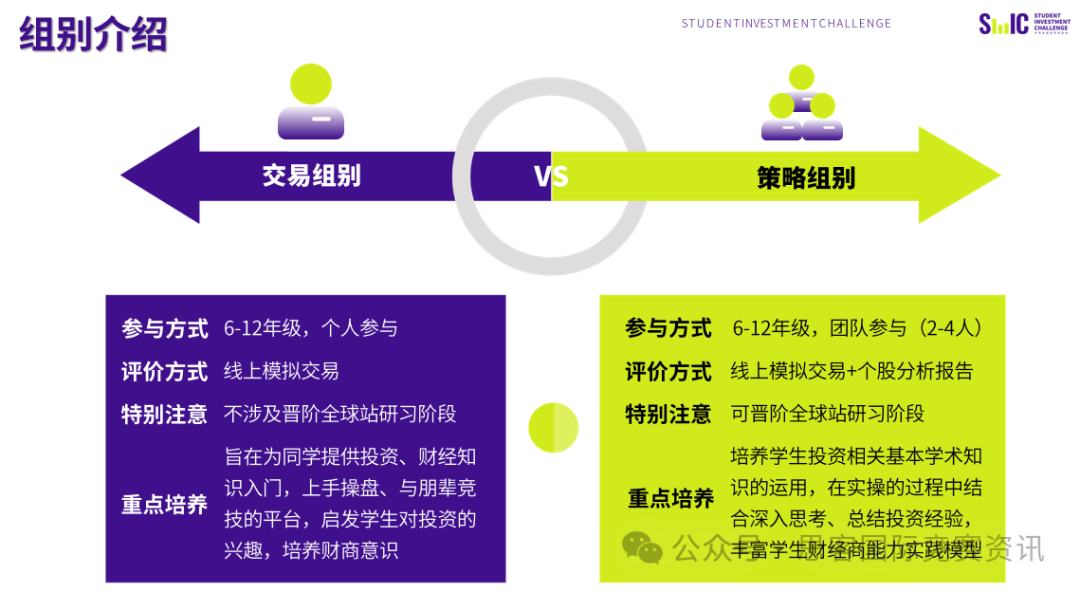
在大家学习的时候,是否时常会有这样的想法:这个东西背后的底层逻辑到到底是什么?
每当学习新知识的时候,都会有这样的疑问浮在脑海。如果不能理解它的底层逻辑,就很难去理解在它基础上构建的知识。
💡GPT正属于这类型。
就算看了不下于几十篇关于Tranformer的视频、教程,但最后对于Q、K、V还是感到非常迷惑。
今天为各位有同样烦恼的大家整理了这篇文章,希望能解开大家的疑惑!
本文摘自:AI大模型世界

Tranformer
Transformer是一种基于注意力机制的神经网络架构,最初由Google在论文《Attention is all you need》中提出。它摒弃了传统的循环和卷积操作,完全依赖于注意力机制来处理输入序列

我们的整个数据集只包含三个句子,这些句子都是来自电视剧的对话。尽管我们的数据集已经清理过,但在 ChatGPT 创建等现实场景中,清理一个 570GB 的数据集需要大量的努力。
Transformer的本质
Transformer架构:
主要由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与Softmax)四大部分组成。

我们的整个数据集只包含三个句子,这些句子都是来自电视剧的对话。尽管我们的数据集已经清理过,但在 ChatGPT 创建等现实场景中,清理一个 570GB 的数据集需要大量的努力。
详细教程
第一步:定义数据集
用于创建 ChatGPT 的数据集为 570 GB。
但是,我们只是为了说明问题,所以我们使用一个非常小的数据集来执行可视化的数值计算。

这些句子来自于电视剧对话,整个数据集只包含这三个句子。
虽然数据集已经清理过了,但在 ChatGPT 创建等现实场景中,想要清理一个 570GB 的数据集仍然需要大量的努力。
第二步:计算词汇量
词汇量是我们数据集中独特单词的总数。
它可以通过下方的公式计算,其中独特单词的总数为 N 。

词汇量公式,其中 N 为总词数
为了找到 N,需要将我们的数据集分解成单个单词。

计算变量 N
在获得 N 之后,我们执行集合操作以删除重复项,然后即可计算独特单词的数量以确定词汇量。

查找词汇量大小
因此,词汇量大小为23,因为我们的数据集中有23 个独特的单词。
第三步:Encoding 编码
现在,我们需要为每个单独的单词分配一个唯一的数字。

为每个单词Encoding 编码
我们已将单个 Token 视为一个单词并为其分配一个数字,ChatGPT 则会使用此公式将单词的一部分视为单个Token :
1 个Token = 0.75 个单词
Encoding完整个数据集后,现在可以开始选择我们的输入并开始使用Transformer架构工作了。
第四步:计算嵌入Embedding
从我们的语料库中选取一个将在我们的 Transformer 架构中处理的句子。

输入(input)以供 Transformer 使用
已经选择了输入后,需要为其找到一个嵌入向量。原始论文为每个输入词使用了一个 512 维的嵌入向量。

原始论文使用 512 维向量
在我们的情况之下,需要使用较小的嵌入向量维度来可视化计算的进行过程。
由此可见,我们将使用嵌入向量的维度6。
大小 6 是靠经验得来的,也见此公式:
=n > 8.33logN

嵌入输入向量
这些嵌入向量的值介于 0 和 1 之间,我们先用随机数来填充一下矩阵。
随着我们的 transformer 开始理解词语之间的含义,这些值随后会通过计算而更新。
第五步:
计算位置嵌入Positional Embedding
现在需要为我们的输入Input计算位置嵌入Positional Embedding。
根据嵌入向量中第i个值的每个词的位置,有两种计算位置嵌入Positional Embedding的公式:

位置嵌入公式
如图,输入句子是“when you play the game of thrones”,起始词是“when”,起始索引(POS)值为 0,维度(d)为 6。
对于 i 从 0 to 5 ,计算输入句子第一个词的位置嵌入Positional Embedding:

位置嵌入:单词:when
我们可以为我们输入句子(input)中的所有单词计算位置嵌入Positional Embedding。

计算输入的位置嵌入(计算出的值已四舍五入)
第六步:连接位置和词嵌入
Concatenating Positional
and Word Embeddings
在计算位置嵌入后,我们需要添加词嵌入Word Embedding和位置嵌入Positional Embedding。

连接步骤
这个由两个矩阵(词嵌入矩阵和位置嵌入矩阵)组合而成的结果矩阵将被视为编码部分的输入。
第七步:多头注意力
Multi Head Attention
多头注意力由许多单头注意力组成,我们需要组合多少个单头注意力取决于我们。
例如,Meta 的 LLaMA LLM 在编码器架构中使用了 32 个单头注意力。
以下是单头注意力外观的示意图:

单头注意力机制在 Transformer 中有三个输入:查询Query、键Key和值Value。
这些矩阵是通过将之前计算的相同矩阵的转置与词嵌入矩阵和位置嵌入矩阵相加,乘以不同的权重矩阵获得的。
假设,为了计算查询矩阵Query,权重矩阵的行数必须与转置矩阵的列数相同,而权重矩阵的列数可以是任意的;
例如,我们假设权重矩阵中有4列。
权重矩阵中的值是0和1之间随机数,当我们的转换器开始学习这些词的意义时,这些值将随后被更新。

计算查询矩阵Query
同样来看,我们可以使用相同的程序来计算键 和值 矩阵,但权重矩阵中的值必须对两者都不同。

计算键Key和值Value矩阵
由此可见,在矩阵相乘后,得到的结果查询Query、键Key 和值Value如下:

查询、键、值矩阵
现在我们有了这三个矩阵,可以一步一步地开始计算单头注意力了。

查询与键的矩阵乘法
为了缩放结果矩阵,必须重复使用我们的嵌入向量(embedding vector)的维度,即6。

缩放结果矩阵,维度为5
下一步是掩码是可选的,这里我们不计算。
掩码就像告诉模型只关注某个点之前发生的事情,在确定句子中不同单词的重要性时不要窥视未来。它帮助模型以逐步的方式理解事物,而不会通过提前查看来作弊。
因此,我们现在将对缩放后的结果矩阵应用softmax操作。

应用 softmax 到结果矩阵
执行最终的乘法步骤以从单头注意力中获取结果矩阵。

计算单头注意力的最终矩阵
到此已经计算了单头注意力,而多头注意力由多个单头注意力组成,正如之前所述。
下面是它的可视化效果:

多头注意力机制在 Transformer 中
每个单头注意力有三个输入:查询、键和值,每个都有不同的权重集。
一旦所有单头注意力输出它们的结果矩阵,它们将被连接起来,最终的连接矩阵再次通过乘以一组随机初始化的权重矩阵进行线性变换,这些权重矩阵将在 transformer 开始训练时进行更新。
在这种情况下,我们一般考虑的是单头注意力,如果我们在处理多头注意力,它看起来是这样的。

单头注意力与多头注意力
💡在任何情况下,无论是单头注意力还是多头注意力,结果矩阵都需要再次通过乘以一组权重矩阵进行线性变换。

标准化单头注意力矩阵
确保线性权重矩阵的列数必须等于我们之前计算的矩阵(词嵌入 + 位置嵌入)的列数,因为在下一步,我们将把结果归一化矩阵与(词嵌入 + 位置嵌入)矩阵相加。

输出多头注意力矩阵
目前已经计算了出多头注意力的结果矩阵,接下来,将进行添加和归一化步骤。
第八步:添加和归一化
一旦从多头注意力中获取到结果矩阵,我们必须将其添加到我们的原始矩阵中,所以先来做这个。

添加矩阵以执行加法和范数步骤
为了规范化上述矩阵,需要计算每行的均值和标准差。

计算均值和标准差
我们用矩阵中每个值减去对应行的平均值,然后除以对应的标准差。

标准化结果矩阵
添加一个小的误差值可以防止分母为零,从而避免使整个项趋于无穷大。
第九步:前馈网络
在将矩阵归一化后,它将通过前馈网络进行处理。我们将使用一个非常基本的网络,该网络只包含一个线性层和一个 ReLU 激活函数层。这是它的视觉外观:

前馈网络比较
首先,我们需要通过将我们最后计算的矩阵与一组随机的权重矩阵相乘来计算线性层,该权重矩阵在 transformer 开始学习时将更新,并将结果矩阵添加到一个也包含随机值的偏置矩阵中。

计算线性层
在计算线性层之后,我们需要将其通过 ReLU 层并使用其公式。

计算 ReLU 层
第十步:再次添加和归一化
一旦从前馈网络获得结果矩阵后,我们必须得将其添加到从先前添加和归一化步骤获得的矩阵中,然后使用行均值和标准差对其进行归一化。

添加和归一化在前馈网络之后
该加法和归一化步骤的输出矩阵将作为解码器部分中存在的多头注意力机制之一的查询和键矩阵,您可以通过从加法和归一化追踪到解码器部分来理解。
第十一步:解码器部分
到目前来看,我们已经计算了编码器部分,我们所执行的每一个步骤,从编码我们的数据集到将我们的矩阵通过前馈网络传递,都是独特的。
这意味着我们之前没有计算过它们。
但从现在开始,所有即将到来的步骤,即变换器(解码器部分)的剩余架构,都将涉及类似类型的矩阵乘法。
至此,再次查看一下我们的 Transformer 架构。
到目前为止我们已经覆盖的内容以及我们还需要覆盖的内容:

即将进行的步骤插图
我们不会计算整个解码器,因为其中大部分内容包含了与我们已经在编码器中完成的类似计算。
详细计算解码器只会因为重复步骤而使博客变长。相反,我们只需要关注解码器的输入和输出计算。
在训练时,解码器有两个输入。
一个是来自编码器,其中最后一个加和归一化层的输出矩阵作为查询和键,用于解码器部分的第二个多头注意力层。以下是它的可视化(来自batool haider):

可视化来自巴图尔·海德
当值矩阵来自解码器在第一次添加和归一化 步骤之后。
解码器的第二个输入是预测的文本。
但是预测输入文本需要遵循一个标准的令牌包装,使 transformer 知道从哪里开始和在哪里结束。

输入:编码器与解码器的比较
在哪里<start>和<end>是两个新标记被引入。此外,解码器每次只接受一个标记作为输入。这意味着<start>将作为输入,而你必须是它的预测文本。

解码器输入 单词
正如我们已知的内容所看,这些嵌入值充满了随机值,这些值将在训练过程中更新。
计算剩余的块,方法与我们之前在编码器部分计算的方法相同。

计算解码器
在深入任何更详细的内容之前,我们需要理解什么是掩码多头注意力,可以通过一个简单的数学例子来说明。
第十二步:理解掩码多头注意力
在Transformer中,掩码多头注意力就像模型用来关注句子不同部分的聚光灯。
这一点很特别,因为它不让模型通过查看句子后面的单词来作弊。这有助于模型逐步理解和生成句子,这对于像说话或把单词翻译成另一种语言这样的任务很重要。
假设我们有一个以下输入矩阵,其中每一行代表序列中的一个位置,每一列代表一个特征:

输入矩阵,用于掩码多头注意力
现在,让我们了解具有两个头的掩码多头注意力组件
1️⃣线性投影(查询、键、值):假设每个头的线性投影:线性投影(查询、键、值): 假设每个头的线性投影:头 1:_Wq_1,_Wk_1,_Wv_1 和头 2:_Wq_2,_Wk_2,_Wv_2
2️⃣计算注意力分数:对于每个头,使用查询和键的点积来计算注意力分数,并应用掩码以防止关注未来的位置。
3️⃣应用 Softmax:应用 softmax 函数以获得注意力权重。
4️⃣< strong id=0 > 加权求和(值): 将注意力权重乘以值以获得每个头的加权求和。
5️⃣将两个头的输出连接起来并应用线性变换。
做一个简化计算:
假设两个条件:
1️⃣强 _Wq_1 = _Wk_1 = _Wv_1 = _Wq_2 = _Wk_2 = _Wv_2 = _I_,单位矩阵。
2️⃣Q=K=V=输入矩阵

掩码多头注意力(两个头)
步骤将两个注意力头的输出合并成一个单一的信息集。
想象你有2个朋友,他们各自给你提供关于问题的建议,此时合并他们的建议意味着将这两条建议放在一起。这样会便于你更加全面地了解他们的建议。
在 Transformer 模型中,这一步骤有助于从多个角度捕捉输入数据的各个方面,有助于模型在进一步处理中使用更丰富的表示。
第十三步:计算预测单词
输出矩阵必须包含与输入矩阵相同的行数,而列数可以是任何数量。在这里,我们处理6。

解码器输出添加和归一化
解码器的最后一个添加和归一化块的结果矩阵必须展平,以便与线性层匹配,以找到我们数据集(语料库)中每个独特单词的预测概率。

将最后一个加和范数块矩阵展平
这个展平层将通过一个线性层传递,以计算我们数据集中每个独特单词的logits(得分)。

计算对数几率
一旦我们获得 logits,就可以使用softmax函数对它们进行归一化,并找到包含最高概率的单词。

寻找预测的词
因此,根据我们的计算,解码器预测的词是你。

解码器的最终输出
这个预测的单词你将被视为解码器的输入单词,这个过程会一直持续到预测到<end>标记为止。
1️⃣上述示例非常简单,因为它不涉及 epoch 或其他只能使用 Python 等编程语言可视化的重要参数。
2️⃣它只展示了训练过程,而使用这种方法无法直观地看到评估或测试。
3️⃣掩码多头注意力可以用来防止 transformer 查看未来,有助于避免模型过拟合。
本篇文章向各位读者展示了一种非常基础的通过矩阵方法来理解 transformers 数学工作原理的方式。
希望对各位读者有所帮助。
本文摘自:AI大模型世界
BrainBee

Brain Bee脑科学大赛作为一项面向全球中学生的学科竞赛,为名校申请加分的7大顶尖国际竞赛之一,在科研竞赛中含量极高。每年全球超过10万名青少年学生参加。
活动旨在鼓励青少年学生认识和探索人类大脑,今后从事生物、神经科学、医学、心理、化学、计算机、人工智能等相关专业的学习和工作,为脑科学领域的自主创新培养未来人才。
01、参赛人群
5-12年级学生均可报名参加。
Brain Bee组:9-12年级学生
Brain Bee(Junior)组:5-8年级学生
02、2025年比赛时间
报名截止日期:2025年1月1日
地区活动:2025年2月22日
全国活动:2025年3月29-30日
国际活动:2025年7月
💡活动采取地区 -> 全国 -> 国际三级模式。
03、报名方式
地区活动通过基地学校报名,基地学校即日起至2025年1月1日接收学生报名。在此期间,组委会不接受个人报名。
若学生所在学校不是基地学校,组委会将于2025年1月1日-10日开放个人报名渠道,并统筹安排活动场地。
个人报名渠道,将于2025年1月1日公布。
04、比赛形式
闭卷笔试形式。时间为90分钟,共80道题目,分为填空、选择两种题型。
05、奖项设置
地区赛奖项设置:
根据各区(省、直辖市、自治区)内参与学生得分排名,评出一、二、三等奖各若干名。总获奖面维持在40%左右。
全国赛奖项设置:
全国活动奖根据学生各环节总分相加排名,评出Brain Bee脑科学活动全国一、二、三等奖各若干名。总获奖面维持在40%左右。
根据报名学校学生的总体成绩表现,评出团体奖若干名
全国活动名额分配:
全国活动总人数在450人左右
考察内容
考查内容围绕与大脑相关的基础知识,主要包括大脑结构、大脑功能、大脑疾病等。
·本知识大纲适用 2025 年度 Brain Bee 脑科学活动;
·其中内容前带 *部分对 Brain Bee Junior 组不作要求
01、脑基础
大脑的结构(Brain Structure):
大脑的构成及各主要构成部分对应的功能
* 大脑解剖(Brain Anatomy):
能够从图片/标本上识别大脑内部结构和组成部分
神经元(Neuron):
神经元结构及功能
神经递质(Neurotransmitter):
了解常见神经递质的作用
神经元信息传递:
突触传递、*动作电位
* 大脑的发育过程(Development)
大脑可塑性(Plasticity)
大脑的老化(Aging):
了解大脑老化机制及相关疾病(退行性疾病)
02、脑功能
感知(Sense):
视觉、听觉、味觉、嗅觉、触痛觉的生理机制;感知系统障碍;感知系统的保 护(如预防近视等)
学习与记忆(Learning and Memory):
学习、记忆的大脑生理机制;探索提高学习、记忆效率 的科学方法
语言(Language):
语言形成和发展的大脑生理机制;语言障碍
运动(Movement):
运动的神经生理机制;运动障碍;探索如何通过科学的运动促进健康
睡眠(Sleep):
睡眠和觉醒的生理机制;睡眠障碍;探索合理睡眠对人体健康的积极作用
* 应激反应(Stress):
应激反应的类型、生理机制及对人体的影响
动机和情绪(Motivation and Emotion):
动机和情绪的神经生理机制;探索如何自我情绪管理
03、脑疾病
儿童障碍性疾病(Childhood Disorder) :
了解自闭症(Autism)、注意缺陷多动障碍 (Attention Deficit Hyperactivity Disorder)、唐氏综合症(Down Syndrome)、阅读障碍 (Dyslexia)等疾病的症状、成因、治疗
上瘾(Addiction):
了解上瘾的生理机制;*导致上瘾的常见药品及其引发的症状和治疗方式, 包括酒精(Alcohol)、尼古丁(Nicotine)、大麻(Marijuana )、鸦片(Opiates)、兴奋剂 (Psychostimulants)等;探索行为上瘾(如网络游戏等)的成因及防治方式
退行性疾病(Degenerative Disease):
了解阿兹海默症(Alzheimer’s Disease)、肌萎缩侧索硬化 症(Amyotrophic Lateral Sclerosis, ALS)、亨廷顿综合症(Huntington’s Disease)、帕金森症 (Parkinson’s Disease)的症状、成因和治疗
精神疾病(Psychiatry):
了解焦虑症(Anxiety Disorders)、妥瑞氏综合症(Tourette Syndrome)、抑郁症(Depression)、躁郁症 (Bipolar Disease)、精神分裂症 (Schizophrenia)的症状、成因和治疗
脑损伤(Illness and Injury):
了解疼痛 (Pain)、癫痫(Epilepsy)、中风(Stroke)、 *脑瘤 (Brain Tumors)、*多发性硬化(Multiple Sclerosis)、*神经创伤(Neurological Trauma)的症 状、成因和治疗方式
脑疾病相关的公共医学:
探索如何宣传普及脑疾病预防知识、推动社会对脑疾病患者的关注等
04、脑研究及技术等
* 脑科学发展简史
脑成像(Imaging):
了解脑电波(EEG)、正电子成像术(PET)、磁共振成像(MRI)、磁共 振波谱分析(MRS)、功能性磁共振成像(fMRI)等技术原理及应用
* 基因治疗(Genetics)
深脑刺激(Deep Brain Stimulation)
脑机接口(Brain-computer Interface)
* 神经网络和人工智能原理(Neural Network and AI)
* 脑科学法律和伦理(Neurolaw and Ethics)
其他脑科学研究的最新动态,包括基础神经生物学的重大突破、最新的药物和治疗方式
备赛书单


官方参考书《Brain Facts》与进阶阅读书目《Neuroscience:Exploring the Brain》
iGEM国际基因工程机器

iGem(国际基因工程机器大赛),英文名称为International Genetically Engineered Machine competition,简称iGEM。开始于2003年,由麻省理工学院创办,是合成生物学领域全球最具影响力的国际性学术竞赛,比赛内容涉及生物学、计算机科学、工程、艺术设计等多个学科,这个比赛每年会吸引40多个国家和地区的顶尖优秀团队参加,截至目前,累计参加人数达到了8万人。
01、参赛人群
主要为9-11年级的学生,竞赛需要组队参赛。
Overgraduate:至少其中一个队员年龄在正式注册截止时间之前大于23周岁
Undergraduate:所有团队成员在正式注册截止时间之前小于23周岁
High School:所有成员在正式注册截止时间前均为高中生
02、竞赛时间安排(以2024为例)
1-4月:报名和队伍选拔
3-6月:线上学术培训
5-6月:课题拟定
7-8月:线下集训
7-8月:成果汇总
9-10月:项目制作,预备展示
11月上旬:答辩
03、参与形式
需要由一个指导老师带领组队参与,没有人数上限,分三个组别,推荐25人左右一组,完成网上的Team Roster确认参与成员
04、比赛形式
团队赛,自主选题。
iGEM竞赛分为干队和湿队。
即,湿队=学术+研发,干队=市场+营销,学生可以根据自己的兴趣爱好以及学习基础选择干队或者湿队。
团队需要利用标准化生物模块(Biobricks)来构建基因回路,建立有效的数学模型,实现对精致复杂人工生物系统(Artificial Biosystem)的预测、操纵和测量。
05、奖项设置:
分为金银铜牌、赛道奖、特别奖以及最终大奖。
奖牌:将根据评审标准分为金、银、铜奖。
奖项:高中生等级分Grand Prizes,the Special Prizes和 Community-Awarded Prizes三个类别,难度由难至易。
不同年龄段生物竞赛规划
01、7-8年级:挖掘孩子对生物的兴趣
可以尝试Brain Bee(Junior)组
02、9-10年级:学习并巩固生物知识
🔹可以备考入门级竞赛11月的IBO,这适合刚开始学IGCSE的学生,学完后也可以衔接后续BBO&USABO生物竞赛;
🔹同时可以继续挑战Brain Bee组,明年3月开始;
🔹基础扎实的同学可以尝试挑战BBO、USABO检验自己的生物学术能力。
03、10-11年级:基本掌握了高中阶段生物国际竞赛所需的知识主题
🔹10月可以备考ASOB,知识范围非常广泛,可以考察对生物学各个领域,难度略低于USABO;
🔹12月可备考HOSA,HOSA涵盖多个细分学科,且与校内基础课程高度匹配,还衔接大学专业课程;
🔹明年4月份可以同时备考BBO与USABO,两者备考大纲大致相同;且BBO与USABO一般同一天的上午或者下午考试,考试时间互不干涉,如果时间充足,两者可同时参加;
🔹如果有更多时间,想要做更多尝试,也可以备考IGEM,但是要更多的时间备考准备。
【竞赛报名/项目咨询+微信:mollywei007】